Executive summary – what changed and why it matters
Mistral has released the Mistral 3 family: ten open‑weight models including a frontier Large 3 (multimodal, multilingual, granular Mixture‑of‑Experts with 41B active / 675B total parameters and a 256k context window) plus nine Ministral 3 small models in 14B/8B/3B sizes designed to run on a single GPU. The substantive change: Mistral is trying to close the capability gap with closed‑source leaders while pushing a practical efficiency play for enterprises that need low latency, on‑prem deployment, and lower compute costs.
- Launch date: announced Tuesday; family includes one large frontier model (Large 3) and nine small models (Ministral 3 series).
- Key technical claims: multimodal & multilingual Large 3, 256k context, MoE architecture (41B active / 675B total), Ministral 3 runs on single GPU and supports 128k-256k context windows.
Key takeaways for executives
- Business impact: Potentially lower operational cost and latency for production assistants and document workflows by using optimized small models instead of always‑on massive closed models.
- Capability: Large 3 narrows feature gaps with GPT‑4o and Gemini 2 by bundling multimodality and high‑context reasoning in an open model.
- Accessibility: Minist r al 3’s single‑GPU claim expands deployable endpoints – on‑prem, edge, robotics, and offline use cases – which matters for security‑sensitive enterprises and low‑connectivity contexts.
- Risk: Open weights increase responsibility for safety, updates, and compliance; initial benchmarks lag closed models out‑of‑the‑box, so fine‑tuning remains necessary to match performance.
Breaking down the announcement
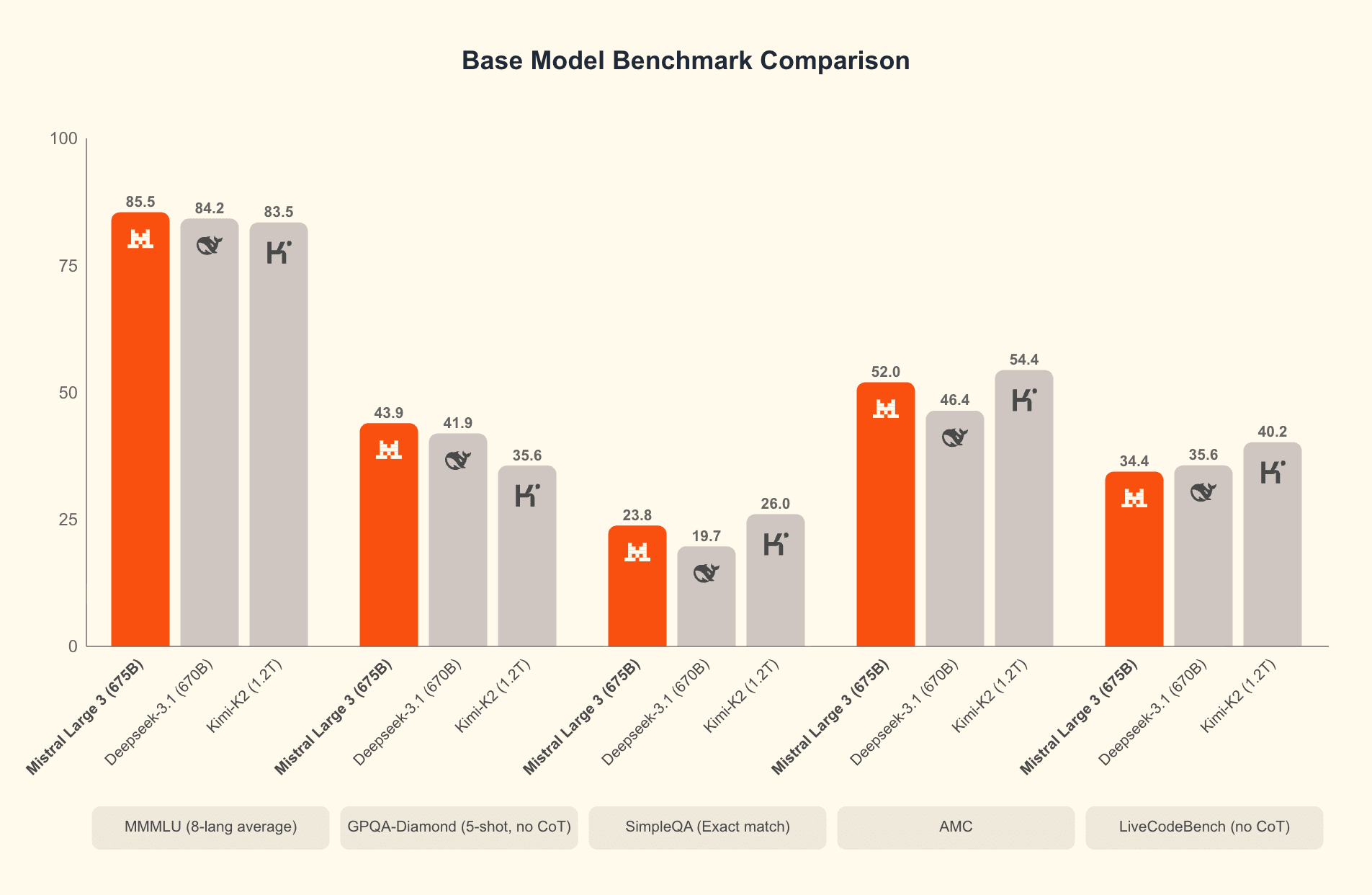
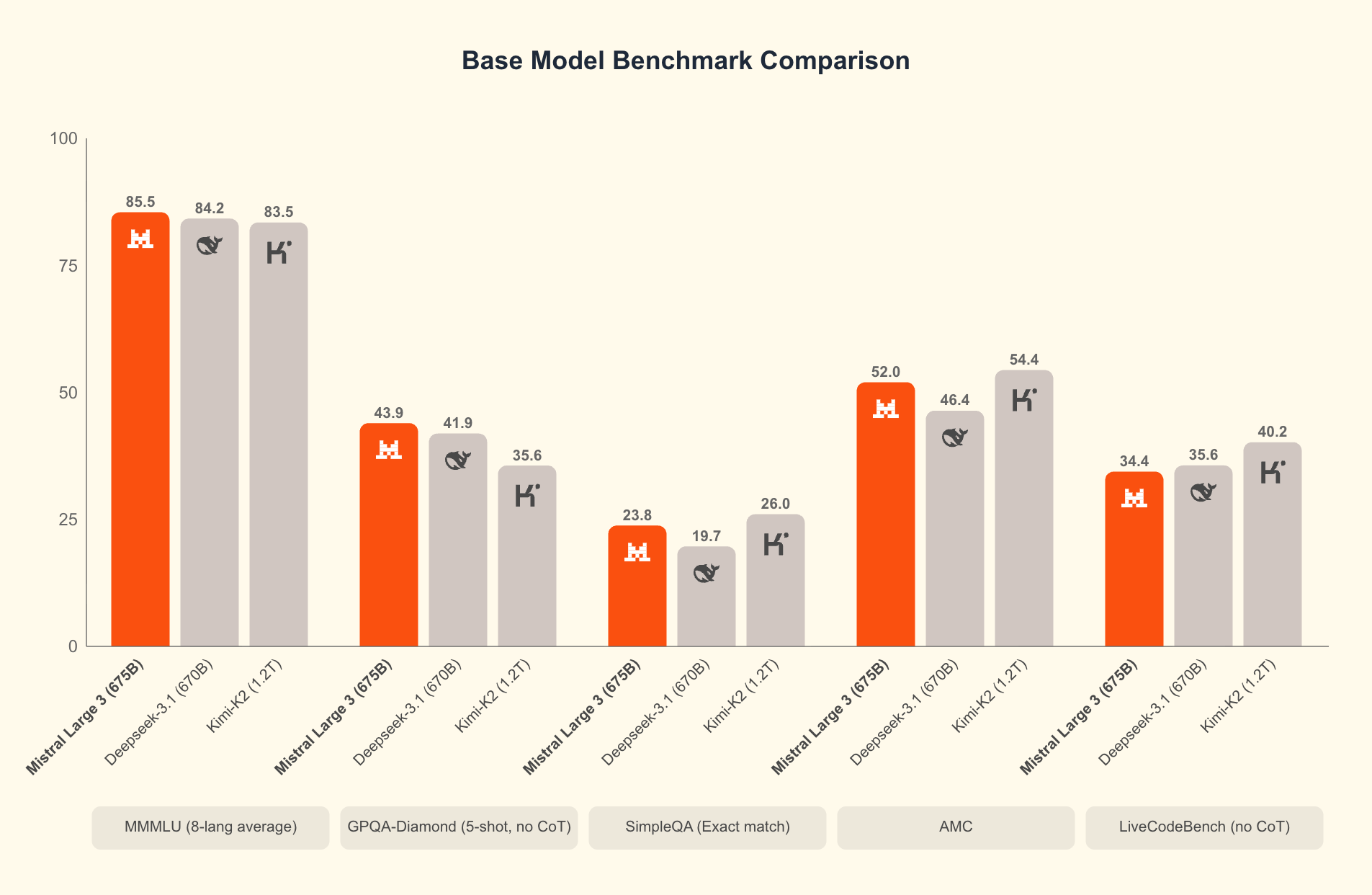
Mistral Large 3 is the headline: an MoE‑style frontier model with a 256k context window intended for long‑document analysis, agent workflows, and multimodal tasks. The MoE architecture reports 41 billion active parameters and 675 billion total parameters — a design that aims to deliver large‑model reasoning while keeping per‑instance compute lower than a dense model of equivalent “total” size.
Ministral 3 is the practical half of the pitch: nine dense models in three sizes and three variants (Base, Instruct, Reasoning). Mistral claims these offer similar or better efficiency than other open‑weight leaders, generate fewer tokens for equivalent tasks, and can be fine‑tuned to match closed models for specific enterprise workflows.
Why now — market and strategic context
Two trends make this release timely: cost/latency pressure in production AI and the maturity of efficient model architectures. Enterprises increasingly prefer deterministic, on‑prem deployments for data residency and reliability. Mistral’s European base and open‑weight stance also map to regional sovereignty debates and procurement preferences.
How it compares — where Mistral stands
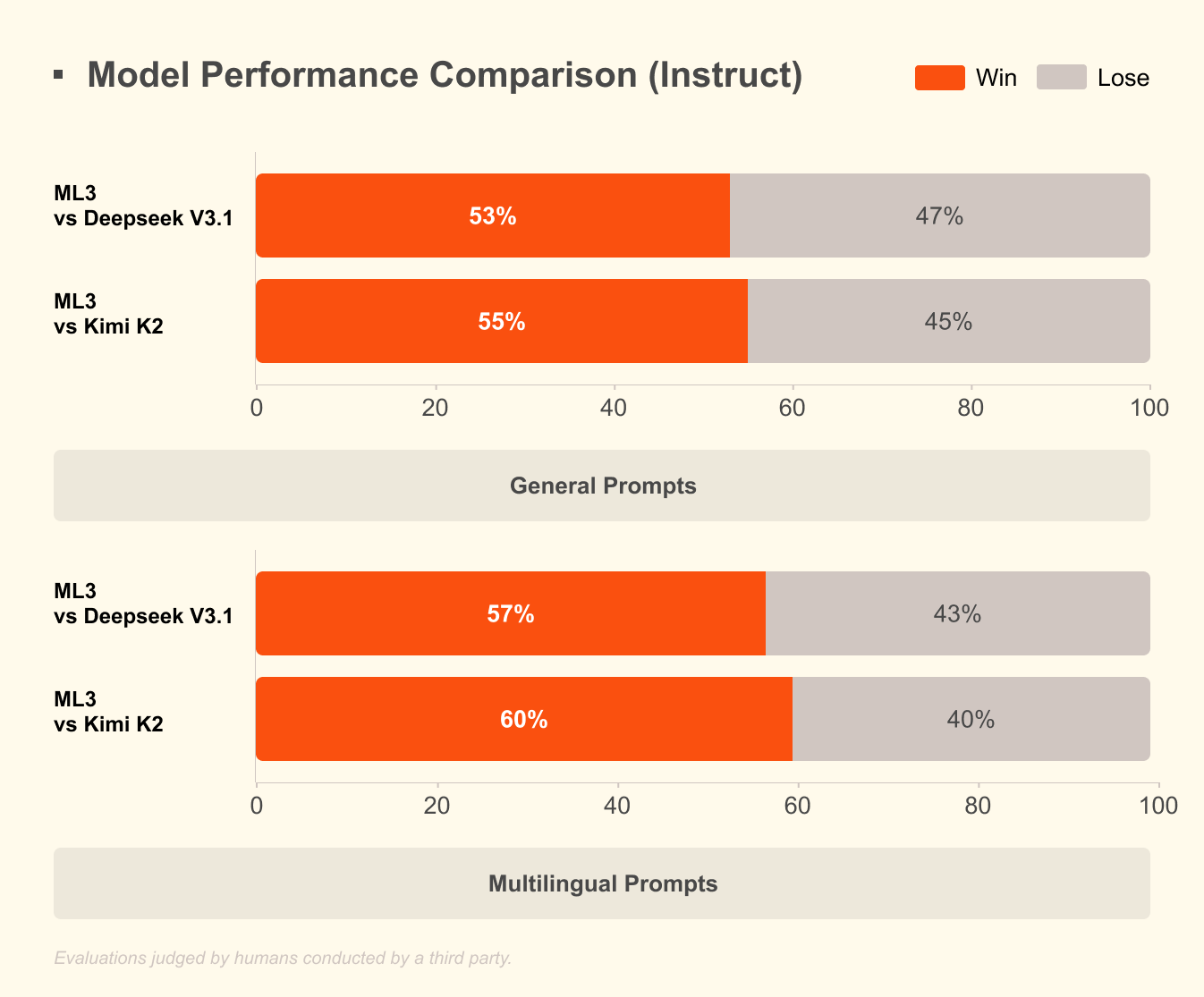
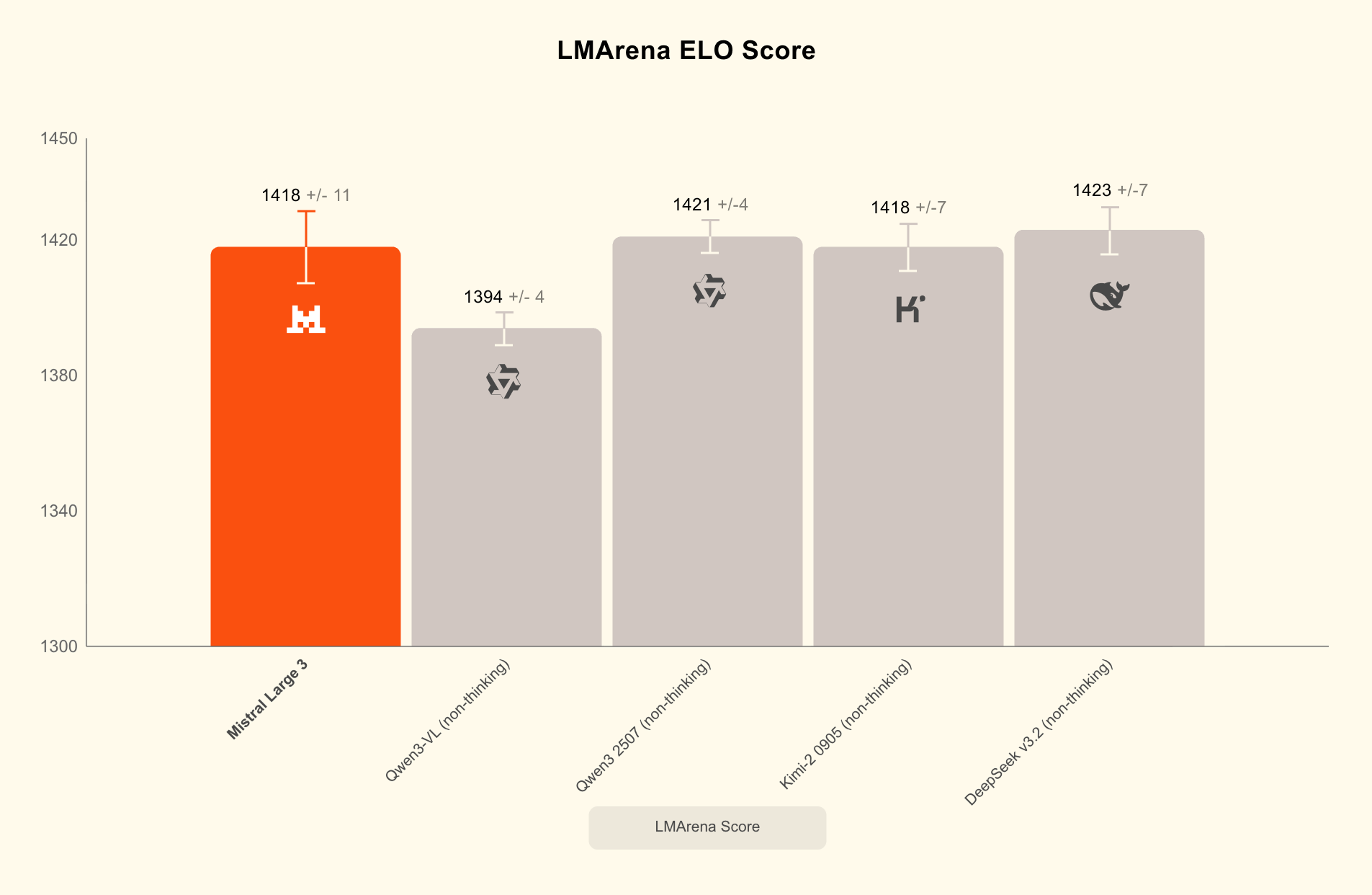
Against closed competitors: GPT‑4o and Google’s Gemini remain ahead in out‑of‑the‑box robustness and end‑to‑end product ecosystems (APIs, tools, guardrails). Mistral’s Large 3 narrows feature parity on multimodality and context length but will need independent benchmarks on accuracy, instruction following, and safety. Against open competitors: it joins the ranks of Llama 3 and Qwen3‑Omni with a full multimodal, multilingual frontier model; its single‑GPU small models directly compete with Cohere’s Command A and other efficiency plays.
Risks, governance, and operational caveats
Open weights raise dual challenges. Operationally, running models on‑prem shifts responsibility for patching, monitoring, and retraining to the buyer—this includes managing prompt‑injection, jailbreak vectors, and model drift. From a governance standpoint, enterprises must assess compliance with data protection, export controls, and industry regulations; local deployment helps with residency but complicates centralized updates and incident response. Finally, safety performance may trail closed systems until robust fine‑tuning and red‑teaming are applied.
Recommendations — immediate next steps for buyers and product leaders
- Run a proof‑of‑value: pilot Ministral 3 for a cost‑sensitive, well‑scoped use case (document search, canned assistant) to measure latency, real TCO, and fine‑tuning effort.
- Require an operational checklist: observability, model signing, patch process, rollback plan, and red‑team evaluation before on‑prem rollout.
- Delay Large 3 for critical tasks until independent benchmarks for hallucination, multimodal accuracy, and safety arrive; use it in noncritical or exploratory projects now.
- Consider hybrid architectures: keep closed APIs for high‑risk, high‑accuracy paths and use tuned Mistral small models for latency‑sensitive or cost‑sensitive endpoints.
Bottom line: Mistral 3 is a calculated bet on practicality — trading absolute out‑of‑the‑box leaderboards for deployability, cost, and control. That trade will appeal to enterprises focused on reliability, offline operation, and data control; it will require disciplined engineering investment to mitigate safety and maintenance risks.


