What Changed-and Why It Matters
Hero, a startup founded by former Meta engineers, launched an invite‑only SDK that autocompletes AI prompts by pre‑filling structured fields (e.g., “to/from/date/airline” for travel, or “style/subject/camera” for image and video). The company says this cuts back‑and‑forth with chatbots and can complete actions up to 10x faster. For operators, fewer chat turns means lower latency, higher task completion, and potentially material token savings at scale-plus a new UI surface for conversion and ads.
Key Takeaways
- Hero’s SDK predicts and fills prompt parameters using a series of models; it’s invite‑only and aimed at consumer and enterprise apps.
- Practical impact: fewer chat turns, faster task completion, and lower server/token costs; Hero claims up to 10x faster flows.
- New surfaces: structured autocomplete opens opportunities for merchandising and ad placement, but raises disclosure and trust issues.
- Competes with in‑house “prompt form” UX, tool schemas, and assistants features from major LLM providers; differentiation is orchestration and packaged UX.
- Early‑stage risk: availability, unknown language coverage, and governance questions around data handling and ad insertions.
Breaking Down the Announcement
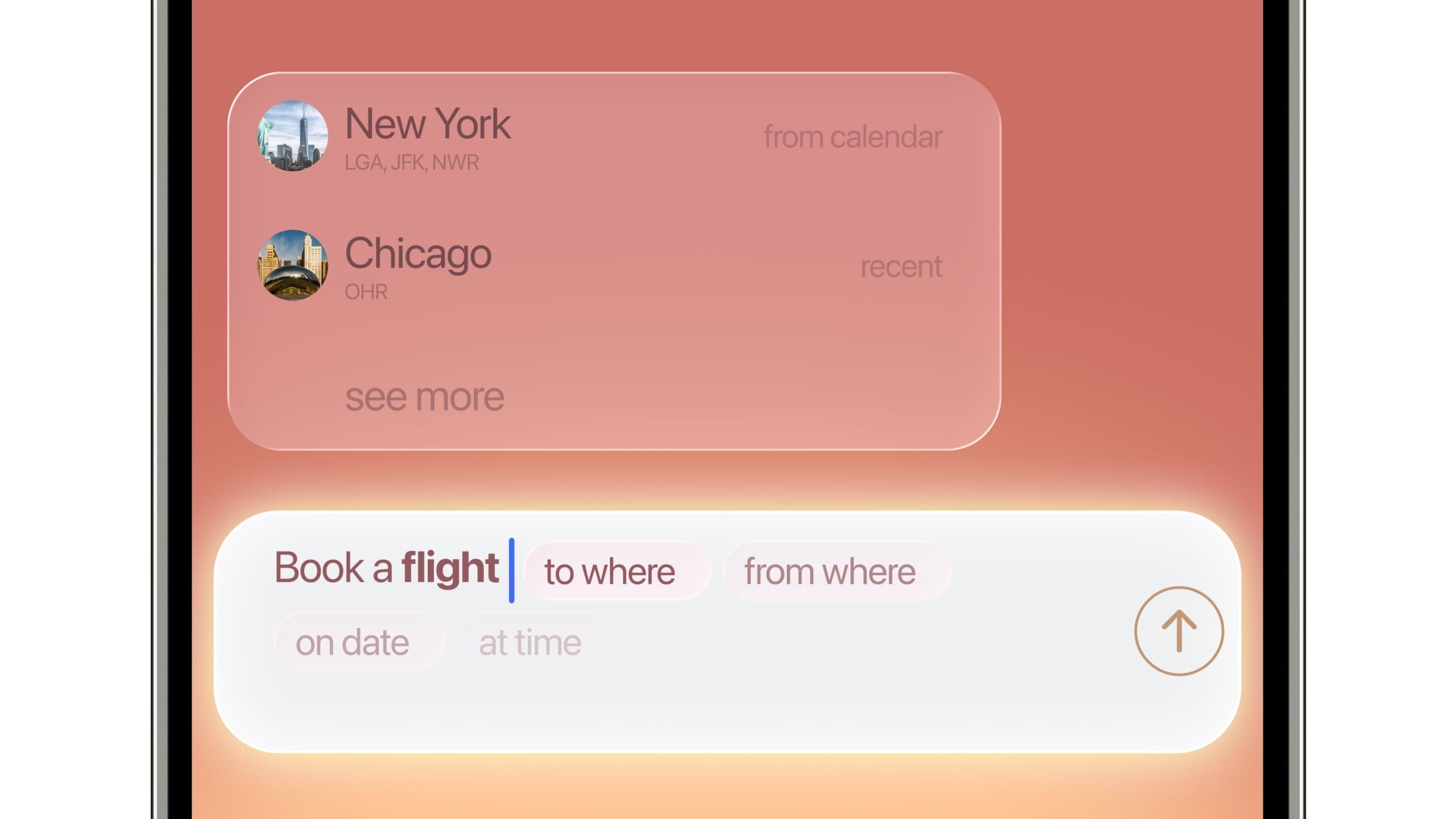
The SDK turns a free‑form prompt into a structured, slot‑filled request in real time. Type “Book a flight,” and it suggests fields like origin, destination, date, time, airline, and return. In creative tools, it scaffolds prompts with dimensions such as subject, style, location, and camera angle. Hero says it uses a series of models to predict the next likely parameters and values, guiding users to a complete, executable request in fewer steps.
Strategically, this is a UX layer on top of LLMs that reduces the need for “prompt engineering” and nudges users toward task‑ready inputs. The company, which raised $4 million in seed funding last year and just added $3 million led by Forerunner Ventures, is also exploring ad monetization inside autocomplete, in talks with Koah Labs to place brand suggestions within predicted fields. Hero is testing the feature in its own app for scheduling and social catch‑ups and expects a release in the coming months.
Technical Perspective and Constraints
Hero describes a “series of models,” which likely means a lightweight domain classifier to detect task type, schema retrieval (which fields apply), and a slot‑filling model to propose values-augmented by lookups (e.g., airport codes) and ranking. That architecture is sensible for latency and cost. However, real‑world reliability will hinge on guardrails: airport disambiguation, time zone handling, brand neutrality, and safe defaults when confidence is low. Expect edge cases where suggested fields are irrelevant or stale and require rapid user correction.
Performance trade‑offs matter. Autocomplete calls add inference steps up front; they should still win if they prevent three to five extra chat turns. As a rough illustration (not vendor data): if a typical flow takes five turns at ~300 tokens per turn (1,500 tokens) and autocomplete reduces that to two turns (600 tokens), usage drops ~60%. At $3-$15 per million tokens, that’s $0.0027-$0.0135 saved per task; at 10 million tasks/month, potential savings are ~$27k-$135k. Latency drops similarly if each LLM round trip averages ~0.8–1.5 seconds.
Industry Context and Competitive Angle
Autocomplete for prompts echoes GitHub Copilot’s impact in code: fewer keystrokes, more structured outcomes. Major platforms already support structured input—OpenAI Assistants and function/tool schemas, Anthropic tool use, and Adobe Firefly’s parameterized fields. Many teams have hand‑built “prompt forms” or used UI kits (e.g., Vercel AI SDK) to constrain inputs.

Hero’s differentiation is packaging: predictive, context‑aware slot filling that generalizes across verticals with model orchestration, rather than per‑app form design. The buy vs. build question will hinge on Hero’s accuracy, latency, analytics, and privacy posture versus in‑house schemas and deterministic typeahead. If your domain is narrow with well‑known fields (e.g., travel), bespoke forms may match or beat Hero. If you run many AI actions across domains, a vendor layer can speed iteration and standardize telemetry.
What This Changes for Operators
Expect higher task completion and lower abandonment in chat‑first experiences. Autocomplete converts vague intents into structured API‑ready inputs, improving downstream reliability (e.g., booking engines, creative renderers, support workflows). It also creates a consistent analytics layer: you can measure fill rates per field, drop‑offs, and which suggestions drive conversion—data that is messy in free‑form chat logs.
- High‑fit use cases: travel search, e‑commerce filtering, customer support triage, creative parameterization (image/video/audio), and enterprise workflows like expense filing.
- Lower‑fit: exploratory research or open‑ended writing where constraints reduce creativity.
Risks, Governance, and Ads
Ad placements inside autocomplete can blur utility with monetization. If brands appear in suggested fields, operators will need explicit “sponsored” labels, opt‑outs, and ranking separation to avoid dark‑pattern accusations. In regulated markets (EU, UK), this touches unfair commercial practices and transparency rules; in the U.S., expect scrutiny under UDAP standards and platform app‑store policies.

Data governance is another priority: clarify whether user prompts and selections are logged for model improvement, how long they are retained, and whether they train third‑party models. Minimization and field‑level redaction (PII in travel details, health in support flows) should be default. Finally, ensure fallbacks when confidence is low—e.g., switch to a deterministic form or ask a single clarifying question—so autocomplete never blocks completion.
Recommendations
- Run A/B tests on 2–3 high‑volume flows comparing Hero vs. a well‑designed deterministic form. Track tokens per task, time‑to‑completion, conversion, and CSAT.
- Instrument confidence gating: require user confirmation for low‑confidence suggestions; log correction rates per field to tune prompts or disable noisy slots.
- Prepare ad governance now: disclosure labels, user controls, policy for brand neutrality, and audit logs of suggestion ranking.
- Secure data pathways: contract for data usage limits, disable data retention for training where possible, and implement field‑level redaction.
- Plan fallbacks: timeouts to standard forms, offline dictionaries for enumerations (airports, SKUs), and clear error states to avoid dead ends.
Bottom line: Hero’s SDK packages a sensible pattern—structured, predictive prompting—that can cut cost and friction where tasks map to known schemas. Treat it as a UX accelerator and analytics boon, but pair with strong disclosure and data controls, especially if you monetize the surface.


