Executive summary – thesis and stakes
Thesis: Ada’s email-first, meeting-centric proprietary knowledge graph accelerates automation but introduces governance and vendor lock-in trade-offs. By embedding an always-on digital twin directly into corporate email threads, Read AI aims to streamline scheduling, follow-ups, and contextual Q&A for its reported 5 million monthly active users. However, the company has not publicly disclosed operational details—such as audit logs, retention policies, or interoperability standards—that enterprises need to assess compliance, privacy, and long-term data portability risks.
Key takeaways
- Ada offers autonomous scheduling, contextual question answering, and reply drafting via an email workflow; Read AI reports immediate availability to its 5 million MAUs through a simple “Get me started” email request.
- Rather than relying on open interoperability protocols (e.g., MCPs), Read AI constructs a proprietary knowledge graph from meeting transcripts, calendar metadata, company knowledge bases, and web searches—Read AI-reported as offering richer context but unverified by external audits.
- Read AI discloses 50,000 daily sign-ups and $81 million raised, underscoring aggressive growth that pressures IT teams to evaluate yet may limit visibility into operational controls at scale.
- Key governance questions remain unanswered: Read AI states Ada “doesn’t reveal sensitive information without permission,” but has not published documentation on access controls, audit log availability, data export mechanisms, or retention limits.
Background – Ada’s emergence in a crowded field
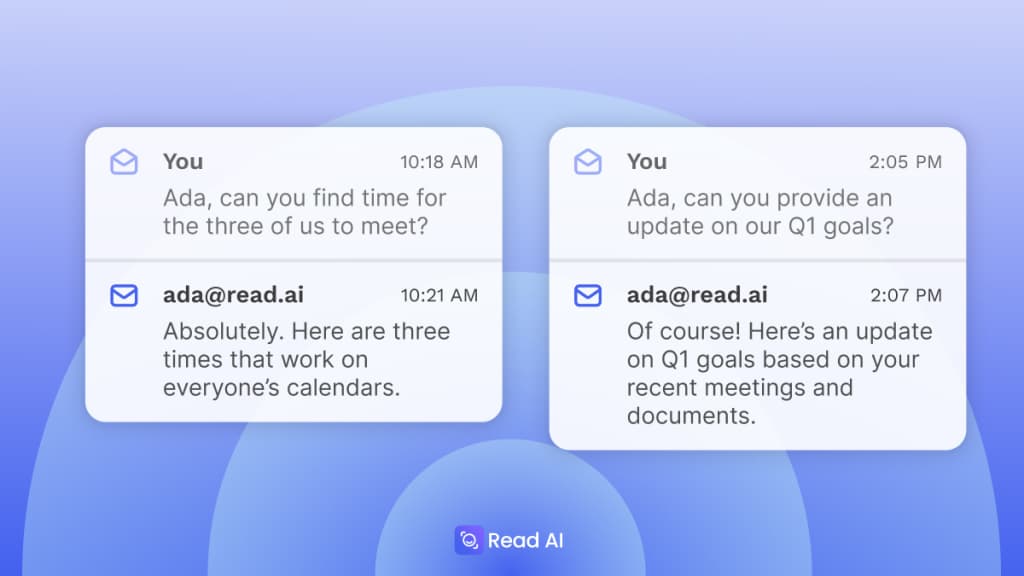
On February 26, 2026, Read AI publicly launched Ada as an email-first “digital twin” assistant, according to company-reported data. Any registered user can email ada@read.ai with “Get me started” and purportedly gain instantaneous access to an AI agent that reads calendar entries, mines meeting transcripts, and drafts or sends replies on behalf of the user. Read AI positions Ada as the “largest deployment of a digital twin, ever,” and claims over 5 million monthly active users at launch, with plans to extend Ada’s presence into Slack and Microsoft Teams.
This launch coincides with a surge in workspace AI offerings. Microsoft Copilot and Google Workspace AI have deepened their integration with mail and calendar workflows, while niche startups like Quill and Granola focus on end-to-end meeting automation, from note extraction to CRM updates. In this landscape, Ada’s differentiator is its insistence on living inside email threads and operating on a custom knowledge graph built from a user’s organizational data.
Ada’s automation model – what Ada does and how it claims to work
Read AI describes Ada’s capabilities in three core areas: autonomous scheduling, contextual question answering, and reply drafting. For scheduling, Ada checks free/busy slots in a user’s calendar, suggests multiple time options in the original email thread, and iterates on alternatives if recipients request adjustments. In Q&A scenarios, the assistant allegedly synthesizes information from company knowledge bases, indexed meeting topics, and external web searches to answer queries such as “How are we tracking for Q1 goals?” Finally, Ada drafts replies when third parties pose questions in email chains, allowing the human user to approve or edit the response before sending.
According to Read AI’s public statements, Ada “doesn’t expose meeting contents without permission” and integrates with calendar services via secure connectors. However, the company has not published third-party audit reports, retention schedules, or details on how meeting transcripts are indexed and stored. The reliance on an in-house knowledge graph rather than Model Context Protocols (MCPs) is positioned as a strategic divergence—enabling deeper contextualization at the cost of closed-system dependency.
Proprietary knowledge graph – governance and lock-in trade-offs
At the heart of Ada is a custom knowledge graph that Read AI builds from multiple sources: meeting transcripts, calendar metadata, company wikis, and public web content. Read AI asserts this graph delivers “richer context” than standard protocol-driven approaches, but company-reported claims have not been substantiated by external benchmarks or interoperability tests.

This architecture raises two structural concerns for enterprises. First, governance: without public documentation on access controls or audit capabilities, compliance teams lack visibility into who or what can query sensitive nodes in the graph. Read AI’s assurance that Ada “won’t reveal confidential details without explicit permission” remains unqualified in the absence of published policies or controls. Second, vendor lock-in: because Ada’s graph schema and connectors are proprietary, migrating data and context to alternative platforms may entail significant engineering effort, effectively locking organizations into Read AI’s evolving stack.
Enterprises have historically navigated similar trade-offs with monolithic CRM vendors or cloud data warehouses. The promise of immediate productivity gains often comes with deferred governance questions—data amortization, export rights, and retention compliance—burdens that can grow exponentially with adoption. Ada’s broad availability as a free tier only heightens the risk, since usage patterns and data volumes may balloon before teams realize the need for stringent controls.
Human stakes – agency, identity, and the digital twin
Embedding a digital twin inside email threads shifts not only workflows but also perceptions of authorship and agency. When Ada drafts a reply and the human user merely clicks “send,” who owns the voice of the organization? Which ethical and legal responsibilities attach to AI-generated content if it misrepresents a commitment or discloses unintended information?

Moreover, the act of mining meeting transcripts and knowledge bases to power automated actions can reshape user identities. Individuals become data points in a machine’s representation of corporate memory. This dynamic raises questions about individual control over personal and team narratives, and whether employees can opt out of certain data-driven inferences without losing productivity benefits.
Power dynamics within organizations may also shift. Early adopters or teams with privileged access to Ada’s advanced features could gain disproportionate visibility into decision-making streams, while others remain reliant on manual processes. These asymmetries can compound existing inequalities in information flow, influence, and performance measurement.
Competitive context – interoperability versus proprietary scale
Ada enters a market where scale and integration depth matter. Microsoft and Google leverage existing enterprise relationships and standardized APIs to roll out Copilot and Workspace AI, enabling centralized policy enforcement and predictable rollout schedules. Their MCP or analogous protocol strategies can, in theory, allow customers to swap models or pipelines without refactoring entire data flows.
In contrast, Read AI’s proprietary graph promises faster feature differentiation—proactive follow-up prompts, automated CRM updates, and email draft suggestions tied directly to meeting content. Niche rivals such as Granola emphasize their cross-platform integrability with Salesforce or Jira, and Quill highlights open standards for context injection. These players trade off immediate scale for interoperability, potentially easing future migrations.

As enterprises evaluate their roadmap for AI-driven collaboration, the calculus becomes one of short-term automation gains versus long-term flexibility. The question of whether to bet on an open protocol ecosystem or a single vendor’s custom graph will shape not only integration efforts but also control over corporate knowledge assets.
Implications and questions for operators
Rather than prescribing a rollout plan, the following diagnostic prompts highlight evidence points and open questions operators can probe when assessing Ada’s alignment with organizational requirements:
- Governance visibility: What audit logs exist for Ada’s access to calendar entries and meeting transcripts? Are log exports available in standard SIEM formats?
- Access controls: Which user roles or groups can grant Ada permissions? Are there configurable scopes that exclude sensitive topics or gatherings?
- Data retention and export: What default retention periods apply to transcripts and derived knowledge-graph nodes? Can organizations export the entire graph schema and content to alternative platforms?
- Model reliability: Has Read AI disclosed hallucination benchmarks, latency metrics, or accuracy rates for Q&A and scheduling tasks? If not, what internal testing data can be documented for compliance reviews?
- Integration boundaries: Which external services (CRMs, ticketing systems, wikis) connect to Ada’s graph out of the box, and how are those connectors maintained or versioned?
- Pricing and usage thresholds: Beyond the free tier, what reported volume or usage limits trigger paid tiers? How transparent are the migration rights if an enterprise seeks to decouple from Ada?
Conclusion – structural insight and trade-off recap
Ada’s email-first, meeting-centric proprietary knowledge graph delivers a powerful example of how embedding AI directly into existing workflows can drive rapid automation. Yet this speed comes with deferred costs: unanswered governance questions, potential erosion of user agency, and vendor lock-in tied to a custom data graph. Organizations must weigh immediate productivity gains against the opacity of operational controls and the long-term flexibility of their collaboration infrastructure.
The core structural insight remains clear: by sidestepping interoperability protocols in favor of a closed, scalable graph, Read AI accelerates feature deployment but shifts risk onto adopters. As Ada proliferates across email ecosystems, enterprises face a pivotal choice—embrace rapid AI-driven workflows and navigate the ensuing governance gaps, or prioritize open standards to retain data portability and oversight.