Executive summary – key structural shift and why it matters
Read AI reports that it has deployed Ada as an always-on “digital twin” email assistant to over 5 million monthly active users, with the company claiming 50,000 daily sign-ups. This represents a shift from reactive meeting transcription to proactive orchestration of email threads and calendars. Read AI’s move hinges on a proprietary knowledge graph built from meeting content, company knowledge bases, and live web searches—a departure from model context protocols (MCPs). While Read AI says this architecture could enable richer contextual responses and automated follow-ups, no independent benchmarks verify these performance gains. The central tension: scaling an email-first agent introduces new layers of privacy, compliance, and provenance risk as organizations cede parts of their scheduling and reply workflows to an AI “twin.”
Breaking down the announcement
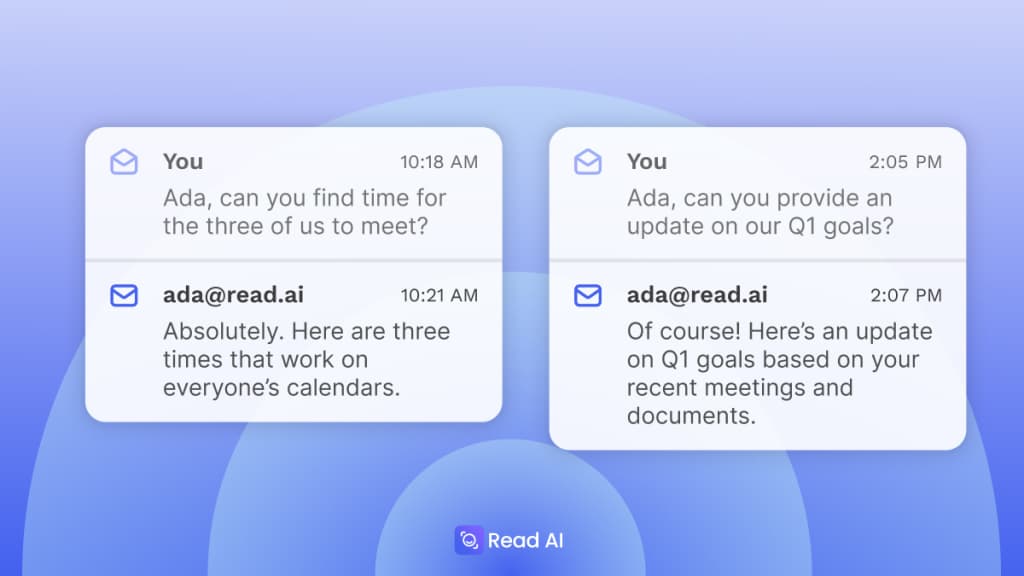
On October 24, 2024, Read AI officially launched Ada, an email-based assistant reachable at ada@read.ai. According to Read AI, users activate the service by emailing “Get me started,” which triggers explicit consent for Ada to read calendar availability and negotiate meeting times directly in email threads. The company claims that Ada drafts and refines replies—for example, summarizing progress against quarterly goals—by sourcing information from integrated knowledge bases, prior meeting transcripts, and live web searches. Read AI emphasizes that Ada does not expose meeting details to external recipients without approval, though independent verification of these privacy controls is absent.
Read AI positions Ada as the evolution of its meeting-intelligence suite. The company’s VP of Product, Justin Farris, has indicated plans for proactive actions such as post-meeting follow-ups and “next-item” scheduling tasks. Future expansions to Slack and Microsoft Teams are slated, according to Read AI’s statements, to broaden the assistant’s reach beyond email. Read AI reports backing from over $81 million in funding and a stated ambition to grow Ada’s installed base to 10 million MAUs, though external sources have yet to confirm these targets.
Technical deep dive – knowledge graph versus MCPs
Read AI claims Ada’s core differentiator lies in its proprietary knowledge graph, which it constructs by parsing meeting transcripts, calendar metadata, and connected service APIs. In contrast, many AI assistants rely on model context protocols (MCPs) that pass along only the most recent conversation tokens to large language models. Read AI asserts that embedding structured nodes for individuals, action items, and document references yields “richer contextual answers than MCP-based integrations,” but no independent performance analyses or frame-time comparisons have been published to substantiate this link.

Key architectural elements cited by Read AI include:
- Graph construction: extraction of entities and relations from meeting transcripts, enriched by company knowledge bases and optional web-search connectors.
- Contextual inference: a blend of graph queries and prompt templates to answer questions like “Who volunteered to update the product spec?” or “What’s next after our Q1 review?”
- Action automation: email negotiation flows that read available calendar slots from Google Calendar and Outlook APIs, insert proposed times into threads, and await user or recipient confirmation.
- Governance guardrails: per-action user approvals, role-based entitlements for enterprise domains, and audit logs that Read AI says track both data access and automated replies.
Read AI reports that no meeting content is stored in unencrypted form and that Ada’s service calls require explicit email verification tokens. However, independent security audits or performance benchmarks have not yet been disclosed, leaving questions about latency, accuracy under load, and resilience to adversarial prompts unanswered.
Competitive context – where Ada fits the landscape
Read AI’s expansion with Ada shifts the meeting-intelligence category toward fully autonomous assistants, blurring the line between digital notetaking and task execution. Startups like Granola and Quill emphasize structured knowledge extraction and niche workflow triggers, whereas platform incumbents such as Microsoft and Google embed assistant features within broader productivity suites. Read AI’s claim to differentiation rests on an email-first interface and a meeting-centric knowledge graph rather than lightweight prompt templates.

That said, larger players benefit from deep directory services and tighter identity integrations, which could grant them more reliable access to corporate calendars, contact lists, and security policies. In parallel, startups can iterate on narrow automation hooks more rapidly but may struggle to scale beyond early adopters without significant infrastructure investment. Read AI’s reported reach of 5 million MAUs offers a deployment scale advantage, yet no independent audits or community feedback (e.g., on Reddit or specialized forums) have surfaced to validate user satisfaction or enterprise readiness.
Governance and privacy risk profile
Deploying an agent that aggregates meeting content and automates user workflows introduces several interlocking risks:

- Data provenance and lineage: Concentrating meeting transcripts, calendar events, and web-sourced information in a knowledge graph raises questions about data retention policies, masking of sensitive entities, and the ability to delete or correct inaccurate entries.
- Consent and delegation: Automated email replies and meeting negotiations require clear audit trails. Read AI reports per-action approval mechanisms, but organizations must evaluate whether these controls align with internal consent models and regulatory frameworks (e.g., GDPR, CCPA).
- Accuracy and operational impact: Mixing internal notes with web search results poses traceability challenges. Unverified or stale suggestions—such as outdated deadline reminders—could lead to misaligned schedules or compliance lapses.
- Third-party exposure: Integrations with calendar services and future Slack/Teams connectors expand the attack surface. Enterprises need to map lateral data flows and assess API permissions to prevent unintended information leakage.
Diagnostic questions shaping procurement debates
Rather than prescriptive rollout steps, organizations procuring AI agents like Ada are raising these diagnostic questions:
- To what extent does the proprietary knowledge graph surface sensitive content, and how can we verify retention and deletion policies?
- Which audit logs are available to trace Ada’s read and write operations in email threads, and do they meet our compliance requirements?
- Has Read AI undergone independent privacy and security assessments, and can the vendor share technical proofs or redacted reports?
- What fallback processes exist if automated replies misfire—how quickly can end users override or retract AI-generated messages?
- How does the architecture handle scale under concurrent negotiation flows, and are there performance benchmarks under realistic enterprise loads?
Outlook – balancing automation gains with governance safeguards
Read AI’s reported deployment of Ada to millions of users embodies a broader industry pivot: AI-powered digital twins moving from passive note-taking to active workflow agents. The company claims that its knowledge graph approach could yield more nuanced, context-aware interactions than MCP-based systems, yet independent validation remains pending. As Ada expands into Slack, Teams, and additional proactive use cases—such as automated follow-up scheduling—enterprises will need to reconcile potential productivity gains with rigorous governance, privacy, and compliance frameworks. The evolving dialogue around auditability, data lineage, and real-world accuracy will ultimately shape how—and how fast—organizations entrust AI with their most sensitive operational tasks.